《算法》第3章:查找。
符号表,二叉查找树,平衡查找树,散列表,应用。
使用符号表这个词来描述一张抽象的表格,将信息(值)存储在其中,然后按照指定的键来搜索并获取这些信息。键和值的具体意义取决于不同的应用。
符号表有时被称为字典,符号表有时又叫索引。本章内容:
3.1 符号表 符号表是一种存储键值对的数据结构,支持两种操作:插入(put)和查找(get)。
符号表最主要的目的就是将一个键和一个值联系起来。
3.1.1 API 所有的实现遵循以下规则:
每个键只对应一个值,不允许存在重复的键;
插入的键值已存在时,会覆盖旧值;
键不能为空,值可以为空。
SearchTable
put(key, value)
将键值对存入表中
get(key) value
获取键对应的值
delete(key)
删除
contains(key) bool
是否有对应的值
isEnpty() bool
是否为空
size() int
键值对数量
keys() []interface{}
表中所有键的集合
3.1.2 有序符号表 对顺序有要求,符号表会保持键的有序并大大扩展它的API。定义一个有序符号表:
最大键max和最小键min:查询其中的最大键和最小键,删除最大键和最小键。优先队列也能实现这些操作,但符号表不能存在重复的键,而且支持的操作更多。
向上取整ceiling和向下取整floor:向下取整,找出小于等于该键的最大键;向上取整,找出大于等于该键的最小键。
排名rank和选择select:排名,找出小于该键的数量;选择,找出排名为k的键。
范围查找keys:在范围中的键。
在基础API的基础上,添加下列方法:
OrderedSearchTable
min() key
最小的键
max() key
最大的键
delMin()
删除最小的
delMax()
floor(key) key
向下取整
ceiling(key) key
rank(key) int
排名
select(int) key
选择排名为该数值的键
size(low, high) int
范围内有多少个键
keys(low, high) keys
返回范围内所有的键
API方法的默认实现:
3.1.3 用例举例 混合使用查找和插入操作。大量不同的键。查找操作比插入操作多得多。
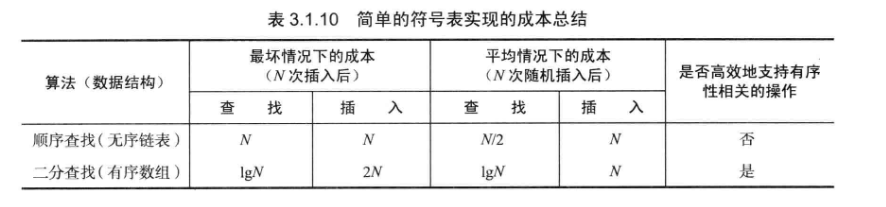
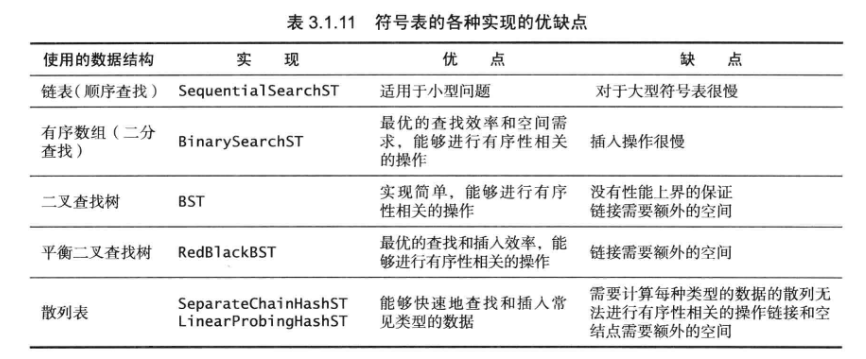
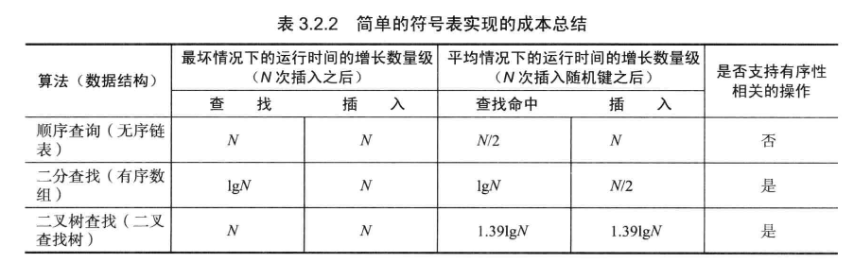
3.1.4 无序链表中的顺序查找 未命中的查找和插入操作都需要N次比较。命中的查找需要N次比较。向一个空表中插入N个不同的键需要~N^2/2次比较。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 type Node struct { key interface {} val interface {} nxt *Node } func NewNode (k, v interface {}, n *Node) return &Node{ key: k, val: v, nxt: n, } } type SequentialSearchST struct { first *Node } func (s *SequentialSearchST) interface {}) interface {} { for x := s.first; x != nil ; x = x.nxt { if x.key == key { return x.val } } return nil } func (s *SequentialSearchST) interface {}) { for x := s.first; x != nil ; x = x.nxt { if x.key == key { x.val = val return } } s.first = NewNode(key, val, s.first) }
3.1.5 有序数组中的二分查找 使用一对平行的数组,一个储存键,一个储存值。
保证数组中键的有序,然后使用数组的索引高效地实现get和其他操作;
核心是rank方法,对于get方法,只要键在表中,rank方法就能精确告诉它的位置;
对于put方法,只要键在表中,rank方法能够精确告诉我们去哪里更新它的值,以及当键不存在时将存储到何处。将更大的键向后移动一格,让键值对分别插入到合适的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 func (st *BinarySearchST) int { return st.size } func (st *BinarySearchST) bool { return st.size == 0 } func (st *BinarySearchST) int ) int { if st.size == 0 { return 0 } lo, hi := 0 , st.size-1 for lo <= hi{ mid := lo + (hi-lo)/2 if st.keys[mid] == key { return mid } if key < st.keys[mid] { hi = mid-1 } else { lo = mid+1 } } return lo } func (st *BinarySearchST) int , lo, hi int ) int { if hi < lo { return lo } mid := lo + (hi - lo) / 2 if key == st.keys[mid] { return mid } if key < st.keys[mid] { return st.rankRecursion(key, lo, mid-1 ) } else { return st.rankRecursion(key, mid+1 , hi) } } func (st *BinarySearchST) int ) interface {} { if st.IsEmpty() { return nil } i := st.Rank(key) if i < st.size && st.keys[i] == key { return st.vals[i] } return nil } func (st *BinarySearchST) int , val interface {}) { rank := st.Rank(key) if st.keys[rank] == key { st.vals[rank] = val } st.keys = append (st.keys, 0 ) st.vals = append (st.vals, nil ) st.size++ for i := st.size-1 ; i > rank; i++ { st.keys[i] = st.keys[i-1 ] st.vals[i] = st.vals[i-1 ] } st.keys[rank] = key st.vals[rank] = val } func (st *BinarySearchST) int { return st.keys[0 ] } func (st *BinarySearchST) int { return st.keys[st.size-1 ] } func (st *BinarySearchST) int ) int { return st.keys[k] } func (st *BinarySearchST) int ) int { rank := st.Rank(key) return rank } func (st *BinarySearchST) int ) int { rank := st.Rank(key) if st.keys[rank] == key { return rank } return rank-1 } func (st *BinarySearchST) int ) { rank := st.Rank(key) if st.keys[rank] != key { return } pre := st.keys[:rank] suf := st.keys[rank+1 :] st.size-- st.keys = append (pre, suf...) }
3.1.6 对二分查找的分析 最多需要lgN+1次比较。
向一个空符号表插入N个元素在最坏情况下需要访问~N^2次数组。
3.1.7 预览
3.2 二叉查找树 一棵二叉查找树BST是一棵二叉树,其中每个结点的键都大于左子树的任意结点的键,而小于右子树任意结点的键。
3.2.1 基本实现 递归很重要。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 type TreeNode struct { key int val interface {} left, right *TreeNode size int } func NewTreeNode (k int , v interface {}) return &TreeNode{ key: k, val: v, size: 1 , left: nil , right: nil , } } func (t *TreeNode) int { return t.size } type BinarySearchTree struct { root *TreeNode } func (t BinarySearchTree) int { return t.root.size } func (t *BinarySearchTree) int ) interface {} { return t.get(t.root, key) } func (t *BinarySearchTree) int ) interface {} { if root == nil { return nil } if key == root.key { return root.val } if key < root.key { return t.get(root.left, key) } else { return t.get(root.right, key) } } func (t *BinarySearchTree) int , val interface {}) { t.root = t.put(t.root, key, val) } func (t *BinarySearchTree) int , val interface {}) *TreeNode { if root == nil { return NewTreeNode(key, val) } if key == root.key { root.val = val } if key < root.key { root.left = t.put(root.left, key, val) } else { root.right = t.put(root.right, key, val) } root.size = root.left.size + root.right.size + 1 return root }
3.2.2 分析 插入操作和查找操作平均比较次数为~2lnN。
3.2.3 有序性相关的方法与删除操作 二叉树得到广泛应用的重要原因是它能够保持键的有序性:
最大键和最小键。最大键:查找右子树。
向上取整和向下取整。向下取整:key小于根结点,在左子树中。大于根结点,小于根结点的右子树,根结点本身。大于根结点的右子树,在右子树中。
选择操作。找到排名为k的键,如果左子树的结点数t大于k,在左子树中;t等于k,就是根结点;t小于k,在右子树查找排名为k-t-1的键。
排名。是选择操作的逆操作。
删除最大键和删除最小键。
删除操作。
范围查找。
性能分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 func (t *BinarySearchTree) int { return t.min(t.root) } func (t *BinarySearchTree) int { if root.left == nil { return root.key } return t.min(root.left) } func (t *BinarySearchTree) int { return t.max(t.root) } func (t *BinarySearchTree) int { if root.right == nil { return root.key } return t.max(root.right) } func (t *BinarySearchTree) int ) int { return t.floor(t.root, key) } func (t *BinarySearchTree) int ) int { if root == nil { return -1 } if key == root.key { return root.key } if key < root.key { return t.floor(root.left, key) } if root.right == nil { return root.key } if rightKey := root.right.key; rightKey > key { return root.key } return t.floor(root.right, key) } func (t *BinarySearchTree) int ) int { return t.ceiling(t.root, key) } func (t *BinarySearchTree) int ) int { if root == nil { return -1 } if key == root.key { return key } if key > root.key { return t.floor(root.right, key) } if root.left == nil { return root.key } if leftKey := root.left.key; leftKey < key { return root.key } return t.floor(root.left, key) } func (t *BinarySearchTree) int ) int { return t.sel(t.root, rank) } func (t *BinarySearchTree) int ) int { if root == nil { return -1 } l := root.left.size if l == rank { return root.key } if l > rank { return t.sel(root.left, rank) } return t.sel(root.right, rank-l-1 ) } func (t *BinarySearchTree) t.root = t.delMax(t.root) } func (t *BinarySearchTree) if root.right == nil { return root.left } root.right = t.delMax(root.right) root.size = root.left.size + root.right.size + 1 return root } func (t *BinarySearchTree) int ) { t.root = t.del(t.root, key) } func (t *BinarySearchTree) int ) *TreeNode { if root == nil { return nil } if key < root.key { root.left = t.del(root.left, key) } if key > root.key { root.right = t.del(root.right, key) } if root.right == nil { return root.left } if root.left == nil { return root.right } }
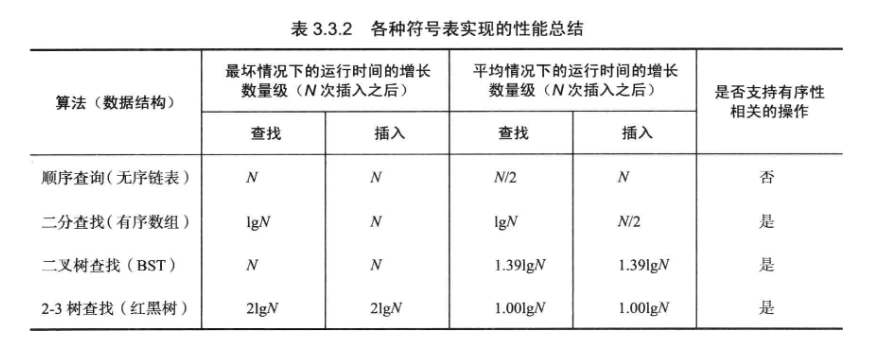
3.3 平衡查找树 顺序查找、二分查找和二叉树查找在最坏的情况下性能还是很糟糕。
平衡查找树,又叫红黑树。无论怎么构造它,运行时间都是对数级别的。
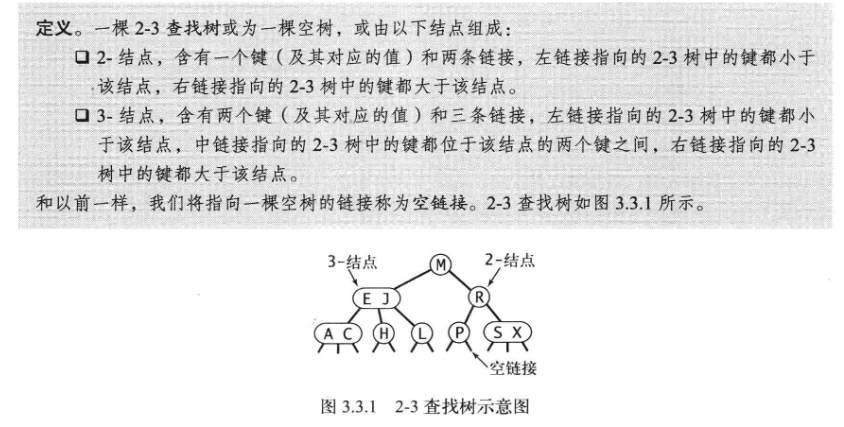
3.3.1 _2-3查找树
3.3.1.1 查找 找到键相同的则查找命中,否则查找未命中。
3.3.1.2 向2-结点插入新键 插入新结点之后,也要保持树是完美平衡的。
如果未命中的查找结束于一个2-结点,那就好办了,将2-结点转换成3-结点即可。
3.3.1.3 向一棵只含有一个3-结点的树插入新键 考虑一般情况之前,先假设这棵树只有一个结点,而且是一个3-结点。
首先临时将新键插入到3-结点中,成为一个4-结点。
然后将中间的键变成左边和右边两个键的父结点。
变成了一棵含有三个2-结点的树。
高度从0变成1。
3.3.1.4 向一个父结点为2-结点的3-结点插入新键 第二轮热身。插入到3-结点变成一个4-结点,然后分解。
并不会为中键创建一个新的结点,而是移动到原来的父结点中。
3.3.1.5 向一个父结点为3-结点的3-结点插入新键 构建4-结点,然后将中键上浮。
一直向上不断分解,直到遇到一个2-结点,或者到达根结点。
3.3.1.6 分解根结点 根结点为4-结点时,分解这个结点,中键变成新的根结点。
3.3.1.7 局部变换 不光在树的底部,在树的任意位置都能进行上述操作。
3.3.1.8 全局性质 局部变换不会影响树的全局有序性和平衡性。
查找和插入操作访问的结点必然不超过lgN个。
3.3.2 红黑二叉查找树
使用红黑二叉查找树来表达并实现2-3查找树。操作如下:
替换3-结点。红黑二叉树背后的基本思想是用标准的二叉查找树和额外信息来表示。链接分为两种类型:红链接将两个2-结点连接起来构成一个3-结点,黑链接是普通链接。
一种等价的定义。红链接均为左链接;没有任何一个结点同时和两条红链接相连;完美黑色平衡,即任意空连接到根结点上的黑链接数量相同。
一一对应。将红链接画平,得到的图像和2-3查找树相同。
颜色表示。颜色用一个布尔值保存。
旋转。某些操作导致出现红色右链接或者两条连续的红链接,使用旋转操作改变红链接的指向。
左旋转:一条红色的右链接转换成左链接。将两个键中较小者作为根结点变成将较大者作为根结点。
右旋转:
旋转后重置父结点的链接。使用左旋转或右旋转的返回值重置父结点。
向2-结点插入新键。新键小于老键,新增一个红色的结点;新键大于老键,新增的红色结点会产生一条红色的右链接,需要左旋转。
向树底部的2-结点插入新键。
向一棵双键树插入新键。有三种情况,每种情况都会产生一个同时连接到两个红链接的结点。
新键大于原树中的两个键。直接将两个链接变为黑即可。其他两种情况最终也会变成这样。
新键小于原树中的两个键。产生两个连续的红链接,此时要将上层的红链接右旋转得到第一种情况。
新键处于两键之间。产生两条连续的红链接。将下层的红链接左旋转得到第二种情况。
红黑转换。局部变换,不会影响整棵树的黑色平衡性。
根结点总是黑色的。
3.3.3 实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 const ( RED = true BLACK = false ) type RBNode struct { key int val interface {} left, right *RBNode size int color bool } func NewRBNode (k int , v interface {}) return &RBNode{ key: k, val: k, size: 1 , color: RED, left: nil , right: nil , } } type RedBlackT struct { root *RBNode } func (t *RedBlackT) bool { return h.color } func (t *RedBlackT) x := h.right h.right = x.left x.left = h x.color = h.color h.color = RED x.size = h.size h.size = h.left.size + h.right.size + 1 return x } func (t *RedBlackT) x := h.left h.left = x.right x.right = h x.color = h.color h.color = RED x.size = h.size h.size = h.left.size + h.right.size + 1 return x } func (t *RedBlackT) h.color = RED h.left.color = BLACK h.right.color = BLACK } func (t *RedBlackT) int , val interface {}) { t.root = t.put(t.root, key, val) t.root.color = BLACK } func (t *RedBlackT) int , val interface {}) *RBNode { if h == nil { return NewRBNode(key, val) } if key == h.key { h.val = val } if key < h.key { h.left = t.put(h.left, key, val) } if key > h.key { h.right = t.put(h.right, key, val) } if h.right.color && !h.left.color { h = t.rotateLeft(h) } if h.left.color && h.left.left.color { h = t.rotateRight(h) } if h.left.color && h.right.color { t.flipColors(h) } h.size = h.left.size + h.right.size + 1 return h }
3.3.4 删除操作
3.3.5 红黑树的性质 高度不会超过2lgN。根结点到任意结点的平均路径长度为~lgN。
3.4 散列表 如果键都是小整数,可以使用数组实现无序的符号表。但是当出现更复杂的键时,就需要用算术操作将键转化为数组的索引来访问数组中的键值对。这就是散列表。散列的查找算法分为两步:
用散列函数将被查找的键转化为数组的一个索引。
出现相同的键,处理碰撞冲突。两种解决方法:拉链法和线性探测法。
散列表是算法在空间和时间上做出权衡的经典例子:
如果没有空间限制,可以直接将键作为数组的索引,这个索引可能是超大的,这样查找操作只需要访问内存一次。
如果没有时间限制,使用无序数组顺序查找。
3.4.1 散列函数 散列函数,目的是将键转化为数组的索引。有一个M大小的数组,就需要一个散列函数将任意键转化成M范围内的数,使0~M-1之间的每个整数都有相等的可能性。无论键是何种类型,都能转化为一个数。当键为:
正整数。最常用的是除留余数法。除数不一定要是10的倍数,这样的话只能利用被除数的后几位。k%97要比k%100好。
浮点数。如果是0-1之间的,将它乘以M并四舍五入。有缺陷,这种情况下高位起的作用更大,修正的办法是将键表示为二进制然后再使用除留余数法。
字符串。将字符串作为一个大整数即可,然后使用除留余数法。
组合键。组合起来,例如一个日期,hash = (((day * R +month) % M) * R +year) % M。只需要保证R足够小不溢出。
3.4.2 基于拉链法的散列表 基于拉链法的散列表的性质:
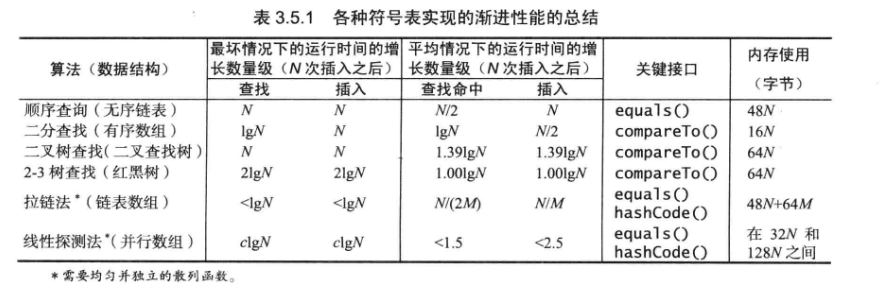
在M条链表和N个键的散列表中,任意一条链表中键的数量均在N/M的常数因子范围内的概率无限趋向于1。
在M条链表和N个键的散列表中,未命中查找和插入操作所需的比较次数为~N/M。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 type ChainingHT struct { N int M int st []SequentialSearchST } func NewChainingHT (m int ) ret := &ChainingHT{ M: m, st: make ([]SequentialSearchST, m), } return ret } func (ht *ChainingHT) int ) int { return key % ht.M } func (ht *ChainingHT) int ) interface {} { return ht.st[ht.hashfunc(key)].Get(key) } func (ht *ChainingHT) int , val interface {}) { ht.st[ht.hashfunc(key)].Put(key, val) }
3.4.3 基于线性探测法的散列表 散列表的另一种实现是开放地址散列表,依靠数组中的空位解决碰撞,用大小为M的数组保存N个键值对,M>N。开放地址散列表中最简单的方法是线性探测法,当发生碰撞时,直接检查散列表的下一个位置,会出现三种情况:
命中,键相同。
未命中,键为空。
继续查找,键不同。
核心思想是,与其把空间用作链表,不如将它们作为在散列表中的空元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 type LinearHT struct { N int M int keys []int vals []interface {} } func NewLinearHT (m int ) ret := &LinearHT{ N: 0 , M: m, keys: make ([]int , m), vals: make ([]interface {}, m), } for i := 0 ; i < m; i++ { ret.keys[i] = -1 ret.vals[i] = -1 } return ret } func (ht *LinearHT) int ) int { return key % ht.M } func (ht *LinearHT) int , val interface {}) { if ht.N >= ht.M / 2 { ht.resize(2 * ht.M) } index := ht.hashFunc(key) for ht.keys[index] != -1 { if ht.keys[index] == key { ht.vals[index] = val return } index = (index + 1 ) % ht.M } ht.keys[index] = key ht.vals[index] = val ht.N++ } func (ht *LinearHT) int ) interface {} { for i := ht.hashFunc(key); ht.keys[i] != -1 ; i = (i+1 ) % ht.M { if ht.keys[i] == key { return ht.vals[i] } } return nil } func (ht *LinearHT) int ) { }
3.4.4 调整数组大小 1 2 3 4 5 6 7 8 9 10 11 func (ht *LinearHT) int ) { t := NewLinearHT(r) for i := 0 ; i < ht.M; i++ { if ht.keys[i] != -1 { t.Put(ht.keys[i], ht.vals[i]) } } ht.keys = t.keys ht.vals = t.vals ht.M = t.M }
3.4.5 内存使用
3.5 应用