Go语言并发和其他
线程和进程的选择,字符串类型的大小,常量,反射,GO并发,Go锁。
1 进程和线程的选择
进程适用于计算密集型,消耗CPU
一个进程中一般有多个exe
windows2000比98稳定:解决了进程内存问题
多线程适用于IO密集型,爬虫,网络速度,文件操作
2 字符串类型的大小
字符串类型在 go 里是个结构, 包含指向底层数组的指针和长度,这两部分每部分都是 8 个字节,所以字符串类型大小为 16 个字节。
3 常量
定义多常量时后一个常量如果没有赋值,与前一个常量值相同,公式也是相同的。
1 | func main() { |
当一组常量都是数值类型,可以使用常量生成器iota指定这组常量按照特定规则变化,iota起始值为0,每次增加1。
1 | func main() { |
无论是否使用iota,一组常量中每个的iota值是固定的,iota按照顺序自增1。每组iota之间无影响。
1 | func main() { |
iota是按行增长的。
1 | const ( |
4 反射reflect
4.1 编程语言中反射的概念
在计算机科学领域,反射是指一类应用,它们能够自描述和自控制。也就是说,这类应用通过采用某种机制来实现对自己行为的描述(self-representation)和监测(examination),并能根据自身行为的状态和结果,调整或修改应用所描述行为的状态和相关的语义。
每种语言的反射模型都不同,并且有些语言根本不支持反射。Golang语言实现了反射,反射机制就是在运行时动态的调用对象的方法和属性,官方自带的reflect包就是反射相关的,只要包含这个包就可以使用。
多插一句,Golang的gRPC也是通过反射实现的。
4.2 interface 和 反射
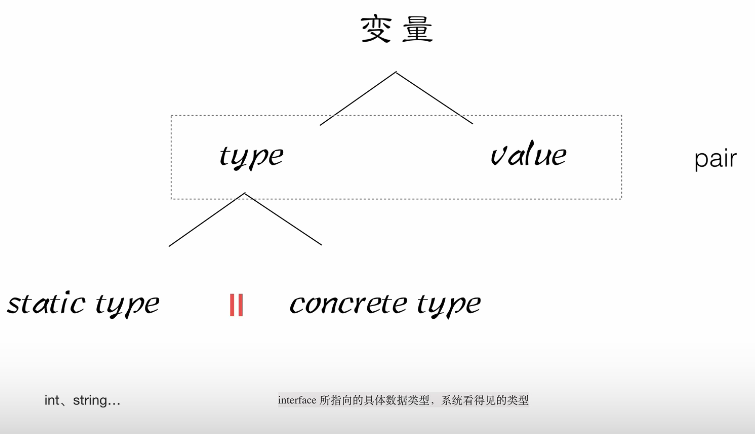
在讲反射之前,先来看看Golang关于类型设计的一些原则
- 变量包括(type, value)两部分
- type 包括
static type和concrete type. 简单来说static type是你在编码是看见的类型(如int、string),concrete type是runtime系统看见的类型 - 类型断言能否成功,取决于变量的
concrete type,而不是static type. 因此,一个reader变量如果它的concrete type也实现了write方法的话,它也可以被类型断言为writer.
接下来要讲的反射,就是建立在类型之上的,Golang的指定类型的变量的类型是静态的(也就是指定int、string这些的变量,它的type是static type),在创建变量的时候就已经确定,反射主要与Golang的interface类型相关(它的type是concrete type),只有interface类型才有反射一说。
在Golang的实现中,每个interface变量都有一个对应pair,pair中记录了实际变量的值和类型:
1 | (value, type) |
value是实际变量值,type是实际变量的类型。一个interface{}类型的变量包含了2个指针,一个指针指向值的类型【对应concrete type】,另外一个指针指向实际的值【对应value】。
例如,创建类型为*os.File的变量,然后将其赋给一个接口变量r:
1 | tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0) |
接口变量r的pair中将记录如下信息:(tty, *os.File),这个pair在接口变量的连续赋值过程中是不变的,将接口变量r赋给另一个接口变量w:
1 | var w io.Writer |
接口变量w的pair与r的pair相同,都是:(tty, *os.File),即使w是空接口类型,pair也是不变的。
interface及其pair的存在,是Golang中实现反射的前提,理解了pair,就更容易理解反射。反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。
1 | package main |
再比如:
1 | package main |
4.3 Golang的反射reflect
reflect的基本功能TypeOf和ValueOf
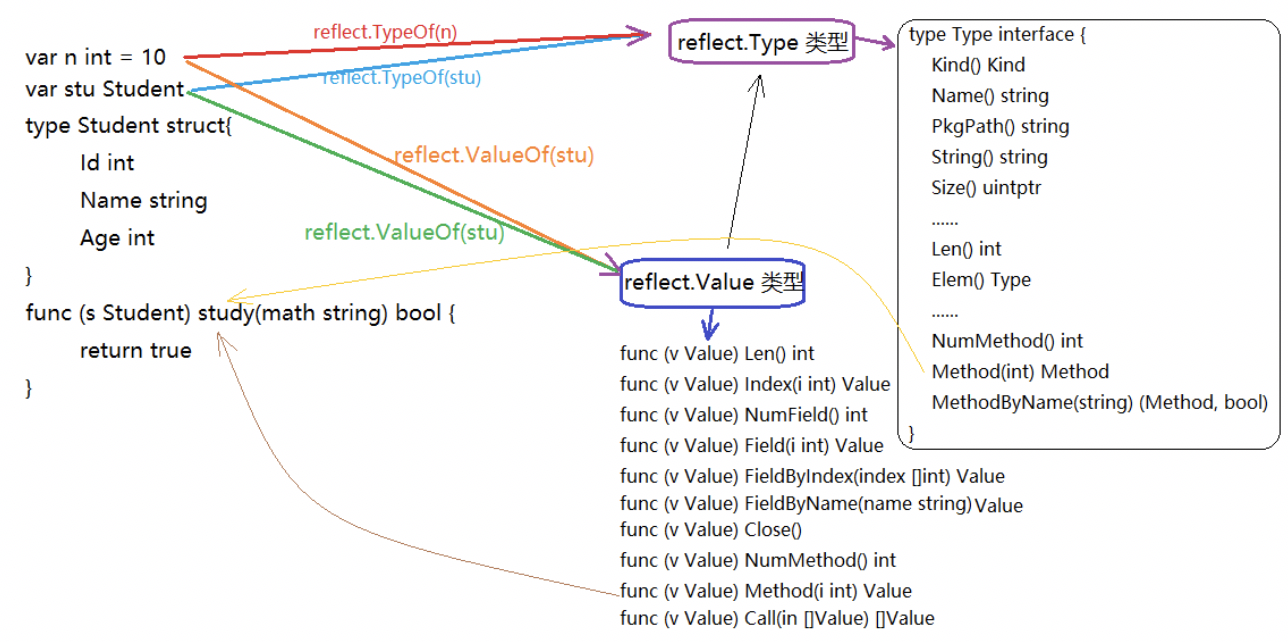
既然反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。那么在Golang的reflect反射包中有什么样的方式可以让我们直接获取到变量内部的信息呢? 它提供了两种类型(或者说两个方法)让我们可以很容易的访问接口变量内容,分别是reflect.ValueOf() 和 reflect.TypeOf(),看看官方的解释:
1 | // ValueOf returns a new Value initialized to the concrete value |
reflect.TypeOf()是获取pair中的type,reflect.ValueOf()获取pair中的value,示例如下:
1 | package main |
说明
reflect.TypeOf: 直接给到了我们想要的type类型,如float64、int、各种pointer、struct 等等真实的类型
reflect.ValueOf:直接给到了我们想要的具体的值,如1.2345这个具体数值,或者类似&{1 “Allen.Wu” 25} 这样的结构体struct的值
也就是说明反射可以将“接口类型变量”转换为“反射类型对象”,反射类型指的是reflect.Type和reflect.Value这两种
从relfect.Value中获取接口interface的信息
当执行reflect.ValueOf(interface)之后,就得到了一个类型为”relfect.Value”变量,可以通过它本身的Interface()方法获得接口变量的真实内容,然后可以通过类型判断进行转换,转换为原有真实类型。不过,我们可能是已知原有类型,也有可能是未知原有类型,因此,下面分两种情况进行说明。
已知原有类型【进行“强制转换”】
已知类型后转换为其对应的类型的做法如下,直接通过Interface方法然后强制转换,如下:
1 | realValue := value.Interface().(已知的类型) |
示例如下:
1 | package main |
说明:
1 转换的时候,如果转换的类型不完全符合,则直接panic,类型要求非常严格!
2 转换的时候,要区分是指针还是指
3 也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量”
未知原有类型【遍历探测其Filed】
很多情况下,我们可能并不知道其具体类型,那么这个时候,该如何做呢?需要我们进行遍历探测其Filed来得知,示例如下:
1 | package main |
通过运行结果可以得知获取未知类型的interface的具体变量及其类型的步骤为:
- 先获取interface的reflect.Type,然后通过NumField进行遍历
- 再通过reflect.Type的Field获取其Field
- 最后通过Field的Interface()得到对应的value
通过运行结果可以得知获取未知类型的interface的所属方法(函数)的步骤为:
- 先获取interface的reflect.Type,然后通过NumMethod进行遍历
- 再分别通过reflect.Type的Method获取对应的真实的方法(函数)
- 最后对结果取其Name和Type得知具体的方法名
- 也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量”
- struct 或者 struct 的嵌套都是一样的判断处理方式
4.4 通过reflect.Value设置实际变量的值
reflect.Value是通过reflect.ValueOf(X)获得的,只有当X是指针的时候,才可以通过reflec.Value修改实际变量X的值,即:要修改反射类型的对象就一定要保证其值是“addressable”的。
示例如下:
1 | package main |
说明:
- 需要传入的参数是* float64这个指针,然后可以通过pointer.Elem()去获取所指向的Value,注意一定要是指针。
- 如果传入的参数不是指针,而是变量,那么
- 通过Elem获取原始值对应的对象则直接panic
- 通过CanSet方法查询是否可以设置返回false
- newValue.CantSet()表示是否可以重新设置其值,如果输出的是true则可修改,否则不能修改,修改完之后再进行打印发现真的已经修改了。
- reflect.Value.Elem() 表示获取原始值对应的反射对象,只有原始对象才能修改,当前反射对象是不能修改的
- 也就是说如果要修改反射类型对象,其值必须是“addressable”【对应的要传入的是指针,同时要通过Elem方法获取原始值对应的反射对象】
- struct 或者 struct 的嵌套都是一样的判断处理方式
4.5 通过reflect.ValueOf来进行方法的调用
这算是一个高级用法了,前面我们只说到对类型、变量的几种反射的用法,包括如何获取其值、其类型、如果重新设置新值。但是在工程应用中,另外一个常用并且属于高级的用法,就是通过reflect来进行方法【函数】的调用。比如我们要做框架工程的时候,需要可以随意扩展方法,或者说用户可以自定义方法,那么我们通过什么手段来扩展让用户能够自定义呢?关键点在于用户的自定义方法是未可知的,因此我们可以通过reflect来搞定
示例如下:
1 | package main |
说明
- 要通过反射来调用起对应的方法,必须要先通过reflect.ValueOf(interface)来获取到reflect.Value,得到“反射类型对象”后才能做下一步处理
- reflect.Value.MethodByName这.MethodByName,需要指定准确真实的方法名字,如果错误将直接panic,MethodByName返回一个函数值对应的reflect.Value方法的名字。
- []reflect.Value,这个是最终需要调用的方法的参数,可以没有或者一个或者多个,根据实际参数来定。
- reflect.Value的 Call 这个方法,这个方法将最终调用真实的方法,参数务必保持一致,如果reflect.Value’Kind不是一个方法,那么将直接panic。
- 本来可以用u.ReflectCallFuncXXX直接调用的,但是如果要通过反射,那么首先要将方法注册,也就是MethodByName,然后通过反射调用methodValue.Call
4.6 Golang的反射reflect性能
Golang的反射很慢,这个和它的API设计有关。在 java 里面,我们一般使用反射都是这样来弄的。
1 | Field field = clazz.getField("hello"); |
这个取得的反射对象类型是 java.lang.reflect.Field。它是可以复用的。只要传入不同的obj,就可以取得这个obj上对应的 field。
但是Golang的反射不是这样设计的:
1 | type_ := reflect.TypeOf(obj) |
这里取出来的 field 对象是 reflect.StructField 类型,但是它没有办法用来取得对应对象上的值。如果要取值,得用另外一套对object,而不是type的反射
1 | type_ := reflect.ValueOf(obj) |
这里取出来的 fieldValue 类型是 reflect.Value,它是一个具体的值,而不是一个可复用的反射对象了,每次反射都需要malloc这个reflect.Value结构体,并且还涉及到GC。
Golang reflect慢主要有两个原因:
- 涉及到内存分配以及后续的GC;
- reflect实现里面有大量的枚举,也就是for循环,比如类型之类的.
4.7 总结
上述详细说明了Golang的反射reflect的各种功能和用法,都附带有相应的示例,相信能够在工程应用中进行相应实践,总结一下就是:
反射可以大大提高程序的灵活性,使得interface{}有更大的发挥余地
- 反射必须结合interface才玩得转
- 变量的type要是concrete type的(也就是interface变量)才有反射一说
反射可以将“接口类型变量”转换为“反射类型对象”
- 反射使用 TypeOf 和 ValueOf 函数从接口中获取目标对象信息
反射可以将“反射类型对象”转换为“接口类型变量
- reflect.value.Interface().(已知的类型)
- 遍历reflect.Type的Field获取其Field
反射可以修改反射类型对象,但是其值必须是“addressable”
- 想要利用反射修改对象状态,前提是 interface.data 是 settable,即 pointer-interface
通过反射可以“动态”调用方法
因为Golang本身不支持模板,因此在以往需要使用模板的场景下往往就需要使用反射(reflect)来实现
5 goroutine
早期的操作系统是单进程的,一次只能执行一个进程,假如在这个过程中进程需要执行IO操作的话,就会阻塞,CPU利用率不高。
然后有了多进程/多线程(在Linux中,线程也是一种进程)的概念,在一个时间段内实现并发。但是由于创建每一个进程都需要分配内存空间,而且需要系统调用,效率低。而线程之间可以共享资源,需要新建的东西少了,效率更高。频繁切换线程和进程也会有效率问题,因为切换需要保存上一个进程的信息,加载下一个进程的信息。进程/线程的数量越多,切换成本越大,越浪费(高消耗CPU)。多线程的竞争,需要锁,开发越来越复杂。
对于一个线程,它的一部分在用户空间,一部分在内核空间,合起来就是一个线程的概念。这个时候能不能分开呢?因为CPU等硬件资源在内核空间,所以只看得到内核空间的部分,将这两个空间分开不影响程序运行。所以把在用户空间的部分叫做协程,在内核空间的部分叫做线程。
既然两个部分不影响,能不能使用一个协程调度器,将一个线程对应多个协程(N:1),这个带来的问题是,当同一个协程调度器里的一个协程阻塞了,其他的协程就无法执行,因为线程只有一个。那就使用多个线程对应多个协程(N:M)。
Golang对协程的处理:一个协程只有几KB的内存,可以灵活调度。
Golang对早期调度器的处理十分糟糕,有一个全局的协程队列,然后有若干个线程对队列里的协程进行竞争执行,即对锁的争夺。缺点是激烈的锁竞争;如果创建一个子协程,会将子协程放入队列,但是往往希望同一个线程执行其子线程,这就为协程的转移造成延迟和额外的负载;CPU在线程之间的切换也造成了低效。
后来的调度器有了GMP模型,从底层往上依次为多个硬件CPU核心,操作系统调度器,多个内核线程,线程争夺的是GOMAXPROCS个Processor处理器,每个P对应一个P的本地队列,队列里有多个协程,还有一个全局队列(上锁)。
调度器的设计策略有复用线程,利用并行,抢占,全局G队列。复用线程有work stealing机制(当一个P里出现阻塞G的话,P队列里后面的G就没法执行了,其他的P就会将后面的G取过来执行),hand off机制(当一个P里出现一个G阻塞时,P将这个G脱离自己的队列,让他依附在M上,自己跑到别的M上执行)。利用并行就是规定GOMAXPROCS=CPU核数/2。抢占就是不再是排队,而是抢占式的,每个G最多执行10ms。全局G队列。
5.1 协程并发
协程:coroutine。也叫轻量级线程。
与传统的系统级线程和进程相比,协程最大的优势在于“轻量级”。可以轻松创建上万个而不会导致系统资源衰竭。而线程和进程通常很难超过1万个。这也是协程别称“轻量级线程”的原因。
一个线程中可以有任意多个协程,但某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。
多数语言在语法层面并不直接支持协程,而是通过库的方式支持,但用库的方式支持的功能也并不完整,比如仅仅提供协程的创建、销毁与切换等能力。如果在这样的轻量级线程中调用一个同步 IO 操作,比如网络通信、本地文件读写,都会阻塞其他的并发执行轻量级线程,从而无法真正达到轻量级线程本身期望达到的目标。
在协程中,调用一个任务就像调用一个函数一样,消耗的系统资源最少!但能达到进程、线程并发相同的效果。
在一次并发任务中,进程、线程、协程均可以实现。从系统资源消耗的角度出发来看,进程相当多,线程次之,协程最少。
5.2 Go并发
Go 在语言级别支持协程,叫goroutine。Go 语言标准库提供的所有系统调用操作(包括所有同步IO操作),都会出让CPU给其他goroutine。这让轻量级线程的切换管理不依赖于系统的线程和进程,也不需要依赖于CPU的核心数量。
有人把Go比作21世纪的C语言。第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持并发。同时,并发程序的内存管理有时候是非常复杂的,而Go语言提供了自动垃圾回收机制。
Go语言为并发编程而内置的上层API基于顺序通信进程模型CSP(communicating sequential processes)。这就意味着显式锁都是可以避免的,因为Go通过相对安全的通道发送和接受数据以实现同步,这大大地简化了并发程序的编写。
Go语言中的并发程序主要使用两种手段来实现。goroutine和channel。
5.3 什么是Goroutine
goroutine是Go语言并行设计的核心,有人称之为go程。 Goroutine从量级上看很像协程,它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
一般情况下,一个普通计算机跑几十个线程就有点负载过大了,但是同样的机器却可以轻松地让成百上千个goroutine进行资源竞争。
6 Channel
channel是Go语言中的一个核心类型,可以把它看成管道。并发核心单元通过它就可以发送或者接收数据进行通讯,这在一定程度上又进一步降低了编程的难度。
channel是一个数据类型,主要用来解决go程的同步问题以及go程之间数据共享(数据传递)的问题。
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine 奉行通过通信来共享内存,而不是共享内存来通信。
引⽤类型 channel可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。
6.1 定义channel变量
和map类似,channel也一个对应make创建的底层数据结构的引用。
当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。
定义一个channel时,也需要定义发送到channel的值的类型。channel可以使用内置的make()函数来创建:
chan是创建channel所需使用的关键字。Type 代表指定channel收发数据的类型。
1 | make(chan Type) //等价于make(chan Type, 0) |
当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。
当 参数capacity= 0 时,channel 是无缓冲阻塞读写的;当capacity > 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity个元素才阻塞写入。
channel非常像生活中的管道,一边可以存放东西,另一边可以取出东西。channel通过操作符 <- 来接收和发送数据,发送和接收数据语法:
1 | channel <- value //发送value到channel |
6.2 无缓冲的channel
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何数据值的通道。
这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作。否则,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。
这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
阻塞:由于某种原因数据没有到达,当前go程(线程)持续处于等待状态,直到条件满足,才解除阻塞。
同步:在两个或多个go程(线程)间,保持数据内容一致性的机制。
如果没有指定缓冲区容量,那么该通道就是同步的,因此会阻塞到发送者准备好发送和接收者准备好接收。
6.3 有缓冲的channel
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个数据值的通道。
这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也不同。
只有通道中没有要接收的值时,接收动作才会阻塞。
只有通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
借助函数 len(ch) 求取缓冲区中剩余元素个数, cap(ch) 求取缓冲区元素容量大小。
6.4 关闭channel
如果发送者知道,没有更多的值需要发送到channel的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。这可以通过内置的close函数来关闭channel实现。
l channel不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束range循环之类的,才去关闭channel;
l 关闭channel后,无法向channel 再发送数据(引发 panic 错误后导致接收立即返回零值);
l 关闭channel后,可以继续从channel接收数据;
l 对于nil channel,无论收发都会被阻塞。
6.5 单向channel及应用
默认情况下,通道channel是双向的,也就是,既可以往里面发送数据也可以同里面接收数据。
但是,我们经常见一个通道作为参数进行传递而只希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这时候我们可以指定通道的方向。
单向channel变量的声明非常简单,如下:
1 | var ch1 chan int // ch1是一个正常的channel,是双向的 |
l chan<- 表示数据进入管道,要把数据写进管道,对于调用者就是输出。
l <-chan 表示数据从管道出来,对于调用者就是得到管道的数据,当然就是输入。
7 Select
7.1 select作用
Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
有时候我们希望能够借助channel发送或接收数据,并避免因为发送或者接收导致的阻塞,尤其是当channel没有准备好写或者读时。select语句就可以实现这样的功能。
select的用法与switch语言非常类似,由select开始一个新的选择块,每个选择条件由case语句来描述。
与switch语句相比,select有比较多的限制,其中最大的一条限制就是每个case语句里必须是一个IO操作,大致的结构如下:
1 | select { |
在一个select语句中,Go语言会按顺序从头至尾评估每一个发送和接收的语句。
如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有两种可能的情况:
l 如果给出了default语句,那么就会执行default语句,同时程序的执行会从select语句后的语句中恢复。
l 如果没有default语句,那么select语句将被阻塞,直到至少有一个通信可以进行下去。
8 锁
Go语言中的互斥锁和读写锁(Mutex和RWMutex) - 雪山飞猪 - 博客园 (cnblogs.com)